点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

标题:Robust Monocular Visual-Inertial Depth Completion for Embedded Systems
作者:Nathaniel Merrill*, Patrick Geneva*, and Guoquan Huang
机构:University of Delaware
来源:ICRA 2021
编译:叶霆锋
审核: wyc

摘要

大家好,今天为大家带来的文章是
Robust Monocular Visual-Inertial Depth Completion for Embedded Systems
在该文章中,作者增强了其之前提出的最先进的视觉惯性里程计(VIO)系统 ——OpenVINS ,通过使用图像引导填充来自VIO的稀疏深度估计(深度补全),从而产生精准的稠密深度,并同时在嵌入式设备上实现完整的VIO+depth系统的实时性能。
从VIO系统产生的具有不同稀疏度的噪声深度值不仅会损害预测稠密深度图的准确性,而且要比来自具有相同底层架构的纯图像深度网络的深度值差得多。
作者在室外模拟和室内手持RGB-D两个数据集上研究了这种敏感性,并提出了简单而有效的解决方案来解决深度补全网络的这些缺点。
文章还讨论了OpenVINS的关键变化,即需要为网络提供高质量的稀疏深度,同时仍然能够对嵌入式设备进行有效的状态估计。作者在不同的嵌入式设备上进行了全面的计算分析,以证明所提出的 VIO 深度补齐系统的效率和准确性。

主要工作与贡献

文章表明,VIO所产生具有可变稀疏性的嘈杂深度值,不仅会损害完整深度图的准确性,而且会使它们的预测远差于具有相同基础架构的纯图像深度网络。
文章提出了新的解决方案来解决这些缺点并增强该网络架构,这些解决方案几乎可以推广到任何稀疏深度补全网络和数据集中,同时无需改变网络架构。
作者通过利用模拟以及真实的VIO深度输入&#xff0c;在室外模拟MAV和室内手持 RGBD数据集上介绍和评估所提出的方法。需要为网络提供高质量的稀疏深度输入来对OpenVINS引入了一些关键更改&#xff0c;并在嵌入式设备(<10-15W)上实现高效的VIO深度补全。
通过全面的时序实验&#xff0c;作者证明了其所提出的VIO深度补全系统可以实现此目标。

算法流程

初始化算法分为三部分&#xff1a;
1.OpenVINS修改
OpenVINS的核心是一个基于EKF的流形模块化的滑动窗口视觉惯性估计器。其采用了两种不同类型的特征&#xff1a;1&#xff09;SLAM特征和2&#xff09;MSCKF特征。文章首先对MSCKF特征的数量引入限制.其次&#xff0c;在每次特征更新后对所有可以进行三角化的主动跟踪特征执行重新三角化的过程。不仅大大缩小了计算时间&#xff0c;而且还可以得到更精确的稀疏深度。
2. 模拟分析
与现有的RGBD数据集相比&#xff0c;文章的分析是在模拟的户外森林环境下进行的。以此提供一个具有挑战性的深度估计场景和完全密集的真实深度图。
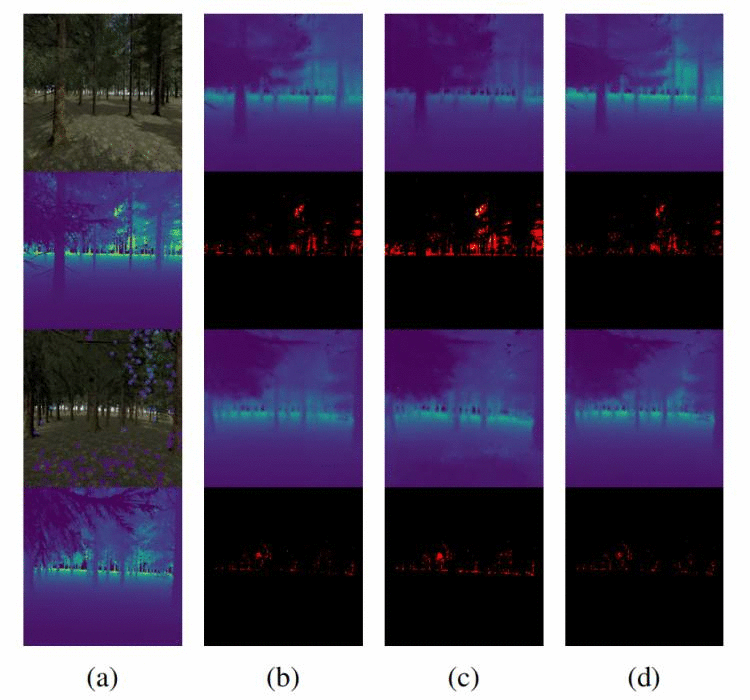
图 1&#xff1a;&#xff08;a&#xff09;来自VIO的RGBsD输入以及真实深度图。(b)仅通过联合每个像素绝对误差的热图来对RGB网络的预测&#xff08;白色较大&#xff09;。(c)经过无噪声训练的深度补全网络的预测效果比RGB网络还要差。(d)所提出的网络通过训练对极端变化的稀疏性水平和噪声深度值具有一定鲁棒性。

表一&#xff1a;使用不同的特征采样方法进行训练的模型在模拟森林环境中的预测结果。比基线差不到 10% 的条目是黄色的&#xff0c;而比基线差至少 10% 的条目是红色的。具有最佳度量的网络在每个部分以粗体显示。
文章使用PyTorch训练本文中的所有网络&#xff0c;通过对深度、角位置和相机姿态的扰动来训练网络&#xff0c;这对于网络能稳健地处理不完美的特征至关重要。为了处理从零到半密集图像不同级别的特征稀疏性&#xff0c;用RGB网络的权重初始化网络和不同稀疏程度的训练来确保网络不会比基线RGB网络更糟。虽然后期融合&#xff08;RGBsD late&#xff09;在准确性方面优于共享编码器&#xff08;RGBsD&#xff09;&#xff0c;但该双编码器网络显然在预测速度方面需要权衡。
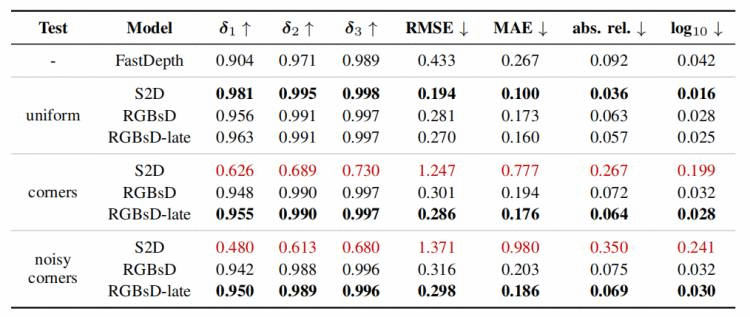
表三&#xff1a;在纽约大学深度 V2 数据集的不同稀疏点选择标准下评估现有方法和提出的网络。

实验结果

1.纽约大学深度V2数据集
本文选择 NYUv2 室内数据集作为基准实验&#xff0c;其中包含了用Kinect 收集的407,024个 RGBD 图像。如表三所示&#xff0c;当在测试期间均匀绘制稀疏点时&#xff0c;S2D ResNet 模型实现了比所提出的网络更高的精度。然而&#xff0c;当使用真实或嘈杂的FAST 角点选择的稀疏点进行预测时&#xff0c;S2D 精度迅速下降&#xff0c;比本文提出的网络和基线RGB FastDepth 更差。这进一步验证了本文之前的分析&#xff0c;即使使用更强大的 ResNet 架构&#xff0c;稀疏深度测试分布的差异也很容易将性能降低到远低于 RGB 网络的水平。
2.在嵌入式平台上的深度补齐
文章在 Jetson TX2 和 Jetson Nano2 设备上评估了所提出的深度补全网络。结果如表4所示&#xff1a;

表4&#xff1a;本文所提出的网络在不同平台上的计时结果。平均超过 1000次网络预测&#xff0c;时间以毫秒为单位&#xff0c;输入图像为 224x224。其中最佳用绿色和次佳用蓝色分别突出显示。
3.在嵌入式平台上运行VIO
第三个实验是评估VIO系统的性能&#xff0c;默认情况下&#xff0c;OpenVINS没有任何多线程或GPU加速。文章在UZH-FPV无人机赛车数据集上进行了设备上的评估。结果如表5所示&#xff1a;
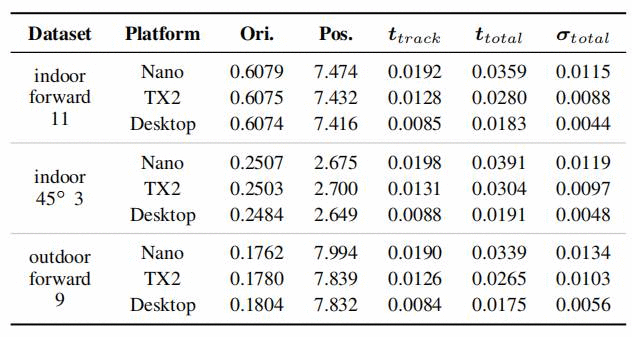
表5&#xff1a;竞争数据集上的相对姿态误差、每米度数和平移百分比&#xff0c;以及执行帧更新的平均时间&#xff08;以秒为单位&#xff09;及其标准偏差。所有误差均基于在线工具报告的结果&#xff0c;该结果是40米、60米、80米、80米、100米、120米子轨迹长度的平均误差。

结论

在这项工作中&#xff0c;作者研究了使用深度补全网络从外部 VIO 系统的嘈杂稀疏深度输入生成密集深度图。为此&#xff0c;作者还定制修改了 OpenVINS&#xff0c;以便为深度补全网络提供更好的输入。同时&#xff0c;由于对具有真实均匀采样深度的深度补全网络进行不成熟的训练会导致比原始纯图像网络更差的准确度&#xff0c;因此还研究了不同的训练方案来解决这些敏感性问题。
最终得出结论&#xff0c;建议从纯图像的权重进行初始化&#xff0c;并使用极其嘈杂的数据进行训练&#xff0c;从而凸显出鲁棒性的巨大优势。该方式训练出的网络通常优于 RGB 网络&#xff0c;作者对 Jetson Nano 和 TX2 嵌入式平台进行了详细的计算分析&#xff0c;结果显示与传统方法相比&#xff0c;本文提出的的状态估计器和深度完成网络良好的实时性能。
点击阅读原文&#xff0c; 即可获取本文下载链接。
本文仅做学术分享&#xff0c;如有侵权&#xff0c;请联系删文。
下载1
在「3D视觉工坊」公众号后台回复&#xff1a;3D视觉&#xff0c;即可下载 3D视觉相关资料干货&#xff0c;涉及相机标定、三维重建、立体视觉、SLAM、深度学习、点云后处理、多视图几何等方向。
下载2
在「3D视觉工坊」公众号后台回复&#xff1a;3D视觉github资源汇总&#xff0c;即可下载包括结构光、标定源码、缺陷检测源码、深度估计与深度补全源码、点云处理相关源码、立体匹配源码、单目、双目3D检测、基于点云的3D检测、6D姿态估计源码汇总等。
下载3
在「3D视觉工坊」公众号后台回复&#xff1a;相机标定&#xff0c;即可下载独家相机标定学习课件与视频网址&#xff1b;后台回复&#xff1a;立体匹配&#xff0c;即可下载独家立体匹配学习课件与视频网址。
重磅&#xff01;3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信&#xff0c;可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群&#xff0c;旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群&#xff0c;目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注&#xff1a;研究方向&#43;学校/公司&#43;昵称&#xff0c;例如&#xff1a;”3D视觉 &#43; 上海交大 &#43; 静静“。请按照格式备注&#xff0c;可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球&#xff1a;针对3D视觉领域的视频课程&#xff08;三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、orb-slam3等视频课程&#xff09;、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕&#xff0c;更有各类大厂的算法工程人员进行技术指导。与此同时&#xff0c;星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息&#xff0c;打造成集技术与就业为一体的铁杆粉丝聚集区&#xff0c;近2000星球成员为创造更好的AI世界共同进步&#xff0c;知识星球入口&#xff1a;
学习3D视觉核心技术&#xff0c;扫描查看介绍&#xff0c;3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题
觉得有用&#xff0c;麻烦给个赞和在看~ 













 京公网安备 11010802041100号
京公网安备 11010802041100号